.png?width=700&height=127&name=Blue%20Mantis%20formerly%20known%20as%20SME%20Solutions%20Group%2c%20Inc.%20(GREEN).png "Blue Mantis formerly known as SME Solutions Group, Inc.")
The best BI solution is the one that automates as much as possible while delivering speed, quality, and flexibility. Bi as a service offers scalable BI solutions that adapt to your business needs without the heavy upfront investment typical of traditional BI tools.
The world of technology and Business Intelligence moves at such a quick pace that we often hear from our clients how difficult it can be to strive for self-service analytics and a true data-literate culture while maintaining data governance and reducing bottlenecks that stifle innovation. To make matters worse, data analytics programs once considered state-of-the-art are now being called legacy systems. The pain is real, and the cost of making a single misstep can be difficult to overcome for years. 
- Self-service analytics generated more dashboards, but without a sound data literate culture in place, self-service analytics turned into self-service datasets. The result was more siloed datasets and errors, not less.
- The data warehouse had terabytes of data and carried significant costs, but it only was used for a few hours a day.
- As data grew, there was no process in place to ensure the data was properly captured and tagged before being validated, cleaned, and governed. By the time it was visualized and analyzed, no one was 100% sure the data could be trusted.
- The BI dashboard tools used were cumbersome to use and the data analysts could not keep up with new requests. By the time the dashboard was built to support the question asked, five more questions were asked and the backlog grew.
- A few dashboards were found to have dirty data. This lack of faith in the data has caused a reduction in user adoption and a shift back towards Excel hell and emailing 20 page reports that no one read.
- We purchased solutions that are too slow, are not trusted, and just waste time and money. We haven't seen any return on our investment.
If any of these hit a little too close to home, you are not alone. The good news is that SME offers a DataOps solution powered by our in-house subject matter experts and industry-leading partners.
DataOps Process: BI as a Service
The goal of SME's DataOps process is to help our clients accelerate their data innovation process while maintaining data safety and governance. This requires carefully evaluating current tools, data literacy, and a sound understanding of our client's end goal. We then work alongside our clients to create a collaborative data management practice that ultimately results in a culture change. When paired with the right tools, a DataOps solution yields faster data iterations with improved quality and a true data-inclusive culture where both non-technical and technical staff flourish.
DataOps Tools: BI as a Service
There is no shortage of data tools on the market. The volume of choices often leads to paralysis by analysis. Our clients resist making any changes for fear of making the wrong choice and paying for it literally and figuratively. Chris Moyer, SME's President and CEO says it best.
"At SME we take pride in vetting and being selective with any partnerships and products that we choose to engage with. We focus on customer pain points and processes, and we align with enterprise products and solutions that actually work, add value, and provide ROI." ~ Chris Moyer, President & CEO at SME Solutions Group

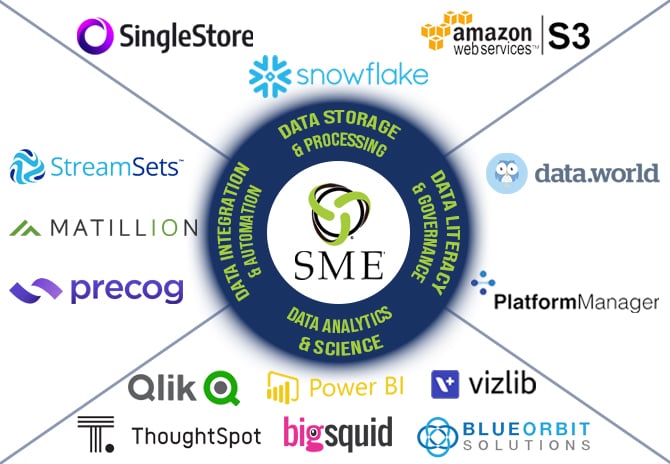
The 4 BI Value Quadrants
In this blog we are going to cover the four areas of expertise where SME shines at delivering Business Intelligence solutions to our customers. We call these the BI Value Quadrants and they discuss common problems and what solutions we employ.
- Data Storage and Processing
- Data Integration and Data Automation
- Data Governance and Data Literacy
- Data Analytics and Science
Data Storage and Processing
Data storage and processing is the heartbeat of a lot of organization's BI deployments. After all, you need to store data somewhere. And usually, you do not store it in one place. Sometimes you have different use cases that call for different ways to have your data be stored, whether it be a database, a data warehouse, or a data lake.
Data Storage Challenges
In the modern day, data analysts are faced with a lot of data silos, or as we like to call it, data sprawl. This derives from legacy systems in the past that couldn't handle multiple workloads. For example, they might be able to handle OLTP, but they required another system for OLAP, data warehousing, time series, and so on. This data sprawl led to multiple data silos that racked up costs because the multiple systems needed for different analyses ended up with a lot of redundant data.
What initiatives are companies implementing to combat these challenges?
The main initiative is to reduce the infrastructure footprint and consolidate as much as possible. This can be done by creating cost effective data warehouses that can house multiple use cases within one system. All of this comes down to what the total cost is and what problems are being solved. Modern data storage solutions avoid the inefficient system of data sprawl.
The business impacts that arise from these initiatives are lowering total costs by consolidating and reducing the infrastructure footprint and being able to take advantage of modern technologies such as auto scaling. Businesses also need to feel confident that their real-time data is in fact real-time. This assurance is even more important for industries with time sensitive data, such as finance companies with fraud and utility and energy companies with meter reads.
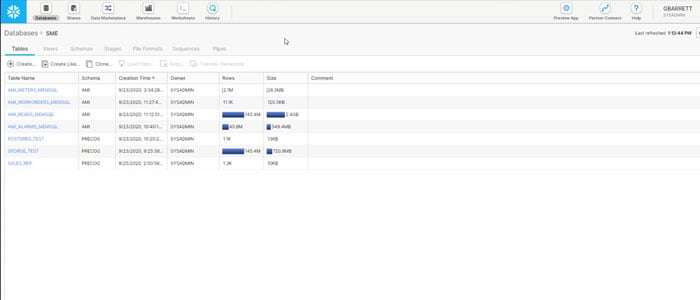
Databases
Not all databases are created equally. Legacy databases are now becoming outdated because as data is growing at an accelerated rate, these systems lack the speed that is needed to keep up. Gigabytes turn into terabytes and are now turning into petabytes. With these growing demands for data, there is also a growing need for speed.
This is where SME’s partnership with SingleStore comes into play. Not only is it a real-time OLTP database, but SingleStore is like a Swiss Army knife that is able to handle all different types of workloads. However, the core focus of SingleStore is that it allows users to accomplish real-time streaming ingest while maintaining sub-second query results. It is a real time system for your streaming data that can handle multiple different types of processing. SingleStore’s most notable feature is its ability to scale out easily. SingleStore can handle not only the terabytes but, nowadays, the petabytes of data.
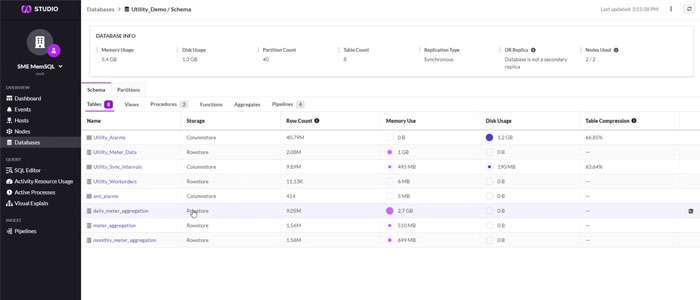
It's not a NoSQL database or document database, so users don’t have to learn a new language, allowing any Database Administration to use it without a problem. SingleStore can also accomplish a variety of different workloads, including time series, geospatial, JSON and more. Users can ingest and transform everything within SingleStore to analyze it inside of one system, effectively reducing data sprawl. Finally, SingleStore allows users to deploy on-premise or in the cloud using the fully managed service in Docker containers. SingleStore is very flexible and can port databases wherever they need to go.
To learn more about our partnership with SingleStore, please visit our dedicated page here or view our SingleStore playlist on YouTube here.
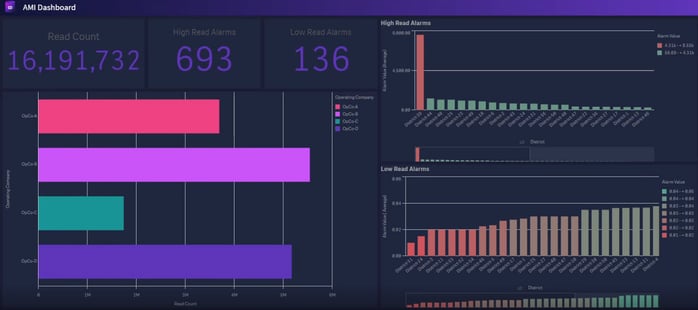

Data Warehouses
The benefits of data warehouses are the ability to consolidate data into one system and then create data marts and archives for the data. Recently there's been a shift from on-premise data warehouses to cloud data warehouses. Utilizing a cloud provider allows companies to consolidate and enrich business data in one central repository. They're also able to use this in a data warehouse where multiple workloads are happening in one system. Many companies' focus is to move their data to a trusted cloud provider, whether that be AWS, Azure, Google Cloud, or Snowflake. Each has its own strengths and SME works to find the best solution for each client.
The shift from on-premise data warehouses to cloud data warehouses is a result of a few pain points that are experienced by many of our clients across multiple industries. Clients often pay large processing fees even when they don’t use them. What they need is more flexibility in scaling and workload to get better control of the storage and computing costs. Snowflake’s auto scaling technology ensures users are only paying for what they use through a separation of storage and compute. For example, if there is a terabyte worth of data but only five gigs are being processed, Snowflake only charges for those five gigs. Cloud data warehouses are exceptional at being able to reduce the costs that legacy data warehouses were known for.
Snowflake also has the ability to create single source data marts. Once data is ready, users can provision data marts or data shares, and reorganize in their own way. The most notable feature Snowflake offers is that because it's zero copy cloning, there's only one copy of the data, even though it may look like it's a data mart. For a lot of our customers, Snowflake fits seamlessly within their BI stack.
Data Lakes and the Storage Layer
There are a lot of different data lake and storage layer options and finding the best option depends on the cloud provider. SME offers a wide variety of hosting options for our customers including servers, data storage, and networking/security. SME has in-depth expertise with AWS, Azure, and Google Cloud. AWS is SME's preferred cloud vendor.
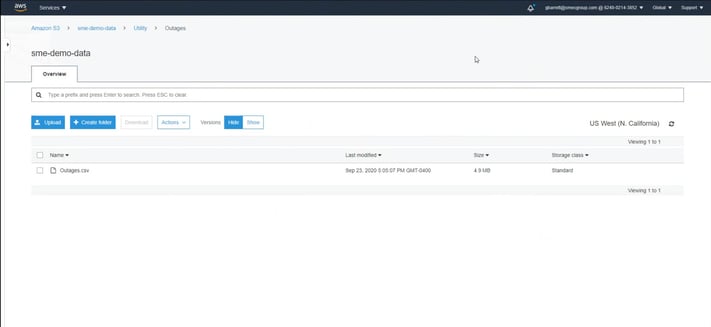
In terms of a data lake, we try to take advantage of the cost-effective object store, which is what Amazon S3 is. It allows users to store semi-structured data, unstructured data, like videos or music, or any other type of data all in one place to be used in a variety of different applications. One of the benefits of S3 is that users can stage and provision their data before they move it into a data warehouse or another application.
We also leverage Spark through Databricks, AWS EMR, or other options, where users can transform the data within the data lake and create different layers of provision data, so it can be ready for downstream applications. Finally, Amazon S3 can connect with hundreds of modern and legacy tools, including SingleStore and Snowflake, at an accelerated speed. It truly is a powerful data lake and an efficient way to rearchitect a data infrastructure before data is moved into other tools.
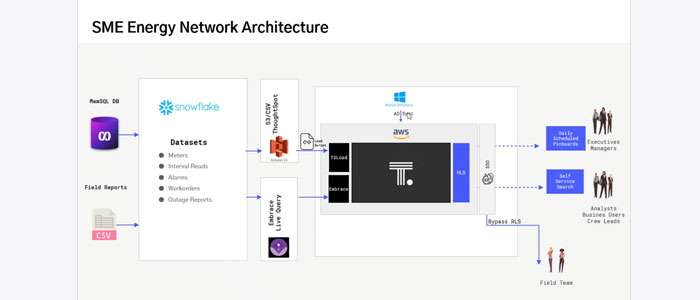
BI as a Service: Data Integration and Data Automation
As we continue our data journey from the databases, data warehouses, and data lakes, we focus on DataOps. Data usually needs to be served up to BI applications, data science platforms, or even other data warehouses and databases, but how do we get that data to go from point A to point B? Being able to create robust data pipelines between systems to make sure that data can move from databases to applications seamlessly is the key to data integration and automation.
Data Integration and Automation Challenges
One of the data integration and automation challenges companies face today is a traditional ETL solution that causes coding bottlenecks due to time-intensive hand coding. Without an automated solution, clients experience a full stop on real-time, up-to-date information, which leads to lost revenue.
Legacy ETL is also traditionally slow. SME has helped companies significantly speed up their ETL by building a modern DataOps platform that is not siloed, can handle all their needs, and enhances the downstream applications to solutions that they are working with. In addition, we make sure that data is delivered in real-time, regardless of whether the real-time is defined as sub-second results or simply once per day. The result is a company that continuously meets its SLAs without the worry of losing real-time analysis.
With modern day data integration platforms, SME helps clients remove the headache by removing the need to rewrite code. We can implement these solutions in days if not hours, while ensuring that the users always have up-to-date data. Looking at some of the partners that we work with in this space, we really try to focus on three distinct pain points. What we see most often with our clients are slow integration jobs, the need for real-time and automation of their data, and the need for modern migration progress to move to upgraded systems.
SME partners with Precog, Matillion, and StreamSets to solve these pain points.
Universal Data Movement: Business Intelligence Solutions

Our goal is to provide a universal data movement platform to connect any data source and push it to any application. With SME’s Data Movement Services and partner Precog, we can connect to different source systems, including a database like SQL Server, Oracle, or even SingleStore. It can be a data lake like S3 or it can be a NoSQL database like MongoDB, Redis, Couchbase, and thousands of API sources.
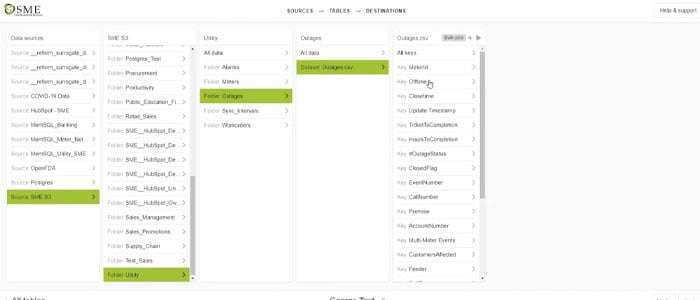
Through the use of Precog’s auto join technology, users can take a JSON document-like structure from an API and flatten them. The resulting interface looks like a table and saves critical time for the user. For example, in SingleStore users can build out the pipelines for Snowflake snow pipes within minutes. The resulting connection always ensures that data moves through the system as fast as possible and never at rest.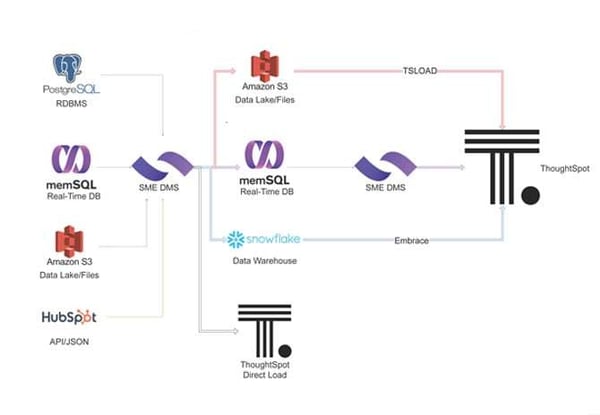
Data Pipeline Automation
Real-time and automated movement of data is crucial to many businesses in a variety of industries. Having access to data in real-time allows businesses to continue making data-driven decisions as quickly as possible.
SME partners with StreamSets, which is geared towards data pipeline automation for all systems. Streamsets has a DataOps approach where users can build a real time data stream as an end-to-end solution. It doesn't have to be just from one source or one destination; it can encompass multiple sources to multiple destinations that have other destinations. StreamSets ensures that users can automate those data pipelines to make sure that data is flowing in a proper way. One of the best things about StreamSets is that it’s able to leverage all these different technologies, whether it's batch, streams, or Change Data Capture, so it's low impact and data can be taken out of the legacy systems and into modern day systems in virtually real time.
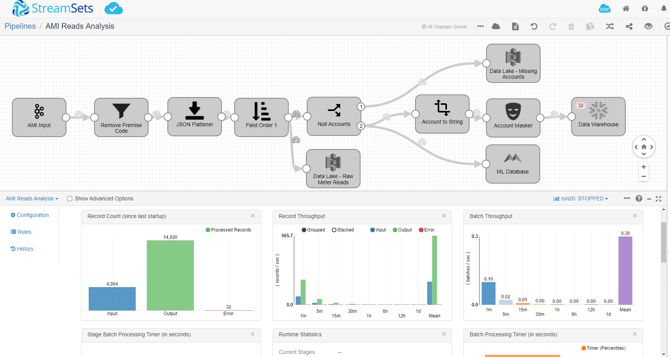
With the StreamSets transformer, users can orchestrate data warehouse and data lake automation, leveraging spark clusters to push code into a data lake, transform the data, and prepare it for a tool like Snowflake or Redshift. All of this can be achieved with zero lines of code. These workflows save 80% in a budget and reduce ETL time from months to days or hours.
Because everything is automated, users have a control hub to monitor their pipelines. Another great feature of StreamSets is that with data drift controls if something changes in the underlying data schema, the data pipeline does not break. Instead, it accounts for it and alerts the users, all while data is continuously being fed. Then users monitor it and repair it, but the pipeline itself is still resilient.
Custom Built ETL Saves Time and Money
SME is partnered with Matillion because they provide purpose-built ELT solutions for all the leading cloud data warehouses. They have five distinct products for Snowflake, Azure Synapse, Google BigQuery, Amazon Redshift, and Data Bricks Delta Lake. All these tools are very specific to those data warehouses. For example, the technologies that are specific to Snowflake allows users to scale up and down. Because Matillion is purpose-built, it allows users to schedule jobs on their schedule and only charges by the hour. So, if ETL is not being utilized for 23 hours of the day, it only charges users for the one hour out of the day, skyrocketing cost savings.
Another great thing about Matillion is that in this ETL, there is no need to hand code anything. Users can simply drag and drop workflows to orchestrate data transformations and the data movement that they have between their systems.
.png?width=725&name=MicrosoftTeams-image%20(2).png)
Matillion also ensures that they land within data warehouses exactly how they're going to be for users’ downstream applications. Even though it is a drag-and-drop interface, what Matillion is really doing is it's orchestrating the SQL and pushing it down into a Snowflake data warehouse. Users don't have to write that code, but they can see the code behind the scenes and understand exactly what Matillion is doing to get their data warehouse ready to go.
Data Governance and Data Literacy
These two terms are being used a lot more nowadays. Data Governance and Data Literacy are core concepts of success in any BI program. This quadrant is truly a blending of the soft skills and business knowledge with the technical skills in terms of how to deliver appropriate data. We want to be able to build out enterprise data catalogs that any user can go to, to learn about their downstream applications, as well as the sources that the data is coming from. If users can access dashboards, but they don't understand the data, or if the data is coming from a source that hasn't been cleaned, then there are no insights into that data. This takes a lot of the value out of your deployments.
At SME, we focus on both the technical side of data governance as well as the softer side of data literacy to make sure that any company, regardless of which tool you're deploying, has BI adoption rate success.
Data Governance and Literacy Challenges
One of the main challenges that arise is that people may not understand the flow of their data. Even with the best data ops pipeline or real time data delivery put in place, data can still fail to tell the correct story if people aren't understanding where the data is coming from or what they're looking at in terms of a dashboard report. This stops users from being able to adopt it or get actionable insights.
It is crucial to be able to make useful business decisions. If users are just delivering projects and not documenting it, or promoting that literate culture, then their projects may not get off the ground and the users may not use them. That will kill any productivity inside of the organization. Therefore, the main pain points clients experience in this quadrant are not having a single, truthful source of data that an entire team can report to, an efficient way to lookup data definitions, or an understanding of the lineage of data.
Some of the key initiatives to solve these pain points are creating a governed data catalog and combining the technical data with a business glossary. Again, this is not just about technical information, metadata, and properties. Without the business context of why something is in there, users are not going to be able to have that productivity when it comes to making actual decisions on their data.
With a data catalog, users can go in, look at a data point and understand the terms, the synonyms, the definitions, and especially the formulas. A data literate culture is going to speed up the business development cycle. A user can get a report, immediately understand it, and go off and make their decisions that they can build their own analysis on
Data Governance
SME works with two partners in this space: data.world and PlatformManager. Data.world is the world's first cloud native enterprise scale data catalog, where users can combine different sources and applications inside of a managed data catalog, create business glossaries, data dictionaries, projects, and more in a one-stop-shop where users can learn more about their data.
The first thing Data.world does when it is deployed is automatically use crawlers to tag metadata properties and the technical information about your data. Users can then assign business definitions and look at the glossaries. Because Data.world is all automated from the technical side, users can see the data lineage from their applications in real time. Rather than just showing sources and destinations, Data.world brings them together to show the underlying business value through the use of a project.
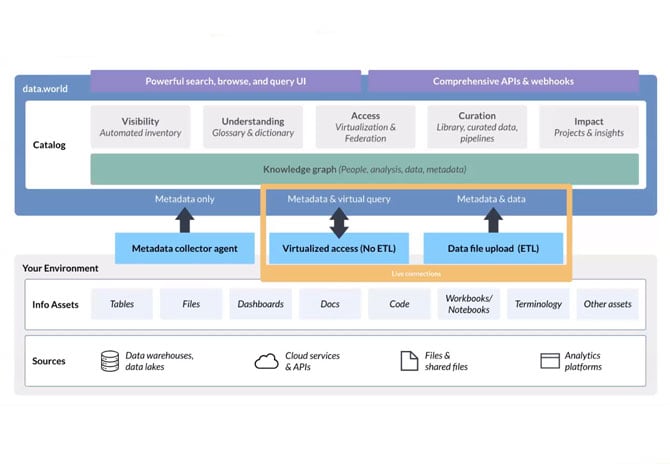
Building out projects allows users to assign data stewards, have conversations within the data, tag other users, add data sets, and more. Data.world is a great way of having a collaborative aspect within data ecosystems.
Finally, users can integrate their data sources. Integration in Data.world is not simply tagging a metadata. This system utilizes the use of federated queries, so users can do SQL queries across Snowflake and join it with Excel data or SQL Server Data. Users can also bring in BI visualizations such as Power BI, even write Python R scripts, through the use of Data.world’s integration with things like Jupyter Notebooks. Data.world is truly a powerful tool because it's bringing all these collaborative efforts into one central location. Not just for technical users, but for business users as well.
SME also partners with PlatformManager in terms of our Qlik deployments to provide version control and lineage. PlatformManager allows users to track the entire application lifecycle and have advanced version control. For example, with GitHub for Qlik environments, users can see previous releases of their applications, make changes and make script comparisons. PlatformManager can also migrate applications from multiple environments. Whether there’s a development, a QA environment, or production environment, PlatformManager can migrate applications in just a few clicks, and all the data, connections, reload tasks, and extensions are all going flow through PlatformManager to the new environment. Any Qlik developer knows that this used to be a huge manual process. It's amazing that it can now be remedied in just a few clicks. PlatformManager also has lineage aspects where users can see an application and track the lifecycle of the data points. For example, a user can easily go in to identify the source data and see that one of their apps extracted that data and stored it as a QVD file, all the way to consistent multiple layers to their endpoints.
PlatformManager also has multi development mode, which allows multiple people to work on a single application, without them stepping on each other's toes. The multi development mode allows you to track changes, lock things in place, ensure that users are able to maximize efficiency by combining their efforts inside of one single application. The result is time saved and a lot less frustration by always knowing which version is current. You can learn more about PlatformManager here or click the button below to watch our webinar with the team at PlatformManager.

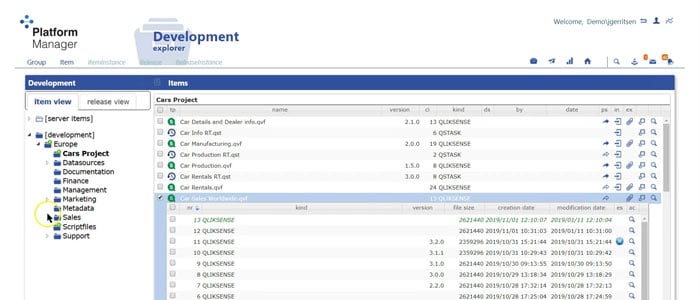
With SMEs expertise, we not only provide the technical solutions, but we also work with the literacy we work with the business to make sure that adoption is expedited, that people are able to understand their data, make those actionable decisions, and in the long run, result in more ROI.
Data Literacy
SME also offers data literacy solutions and training that packages well with any BI deployments. Because the success of these BI tools relies on how well the user is going to adopt it and what their understanding of the data is, SME invests heavily to ensure our employees know data like the back of their hands and can bring that value to any organization. Especially the ones that we work with side by side with their deployments and their development. We understand their pain because we experience them firsthand. We translate those experiences into a data literacy program to help users drive data adoption, improve data trust, and create a truly data-driven environment.
Data Analytics and Science
Up until this point, we've covered most of the data journey for any BI program, and when we talk about Data Analytics and Science, most people have some familiarity with what it is. We're able to take data and transform it into rich interactive visualizations and machine learning models where we're able to make better decisions, because it's presented to us in a more digestible format. SME’s Data Analytics and Science BI quadrant provides better business impacts that save our clients time, money, and ensures that their analytics platforms are up to date.
Data Analytics and Science Challenges
Data analytics in the past required a lot of IT knowledge. Users needed to be able to engineer the data to get it ready and needed a specific skill set to be able to build out visualization. Only a few people were able to build out dashboards or analytics portals, which led to long depth queues, or forced companies to hire more people, which led to higher costs down the road.
So, how do we remedy this? SME works to democratize analytics and AI to the masses and make sure that everybody not only can consume it, but they're also able to build data visualization themselves. This is coming through the introduction of a new wave of business intelligence, where it doesn't require users to have heavy knowledge of the back end, and instead they're able to utilize these tools through a front-end, operating them like a self-service or search-based portal and answer their data questions independently. This revelation reduces the burden on IT and BI developers by relieving some of their workload of simple report building or visualizations.
The analytics and reporting space is a big one, but each tool has a strength that is used to achieve a specific solution. SME works with a wide variety of partners in this space including ThoughtSpot, Qlik, Power BI, and Big Squid.
ThoughtSpot
ThoughtSpot is a search at scale application that allows any user to use the search-based portal that creates visualizations using keyword terms, as well as synonyms. Users can analyze terabytes of data and go up to the highest level to get the most granular level of detail because of it. With this, ThoughtSpot can incorporate AI and machine learning with their Spot IQ engine. When users ask a question, they are able to get additional questions answered using machine learning through the back end. This saves time and makes it easier to spot anomalies and trends. ThoughtSpot’s search at scale application also equenables any type of user to utilize the tool, understand the data, and answer their own questions.
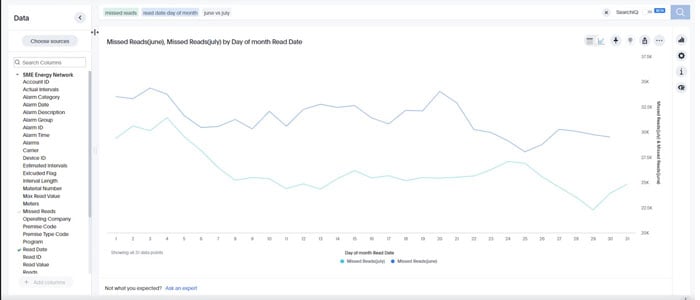
With ThoughtSpot’s Embrace platform, users can also live query data warehouses. If a user has a Snowflake, Redshift, Synapse, or any other type of data warehouse, they can utilize Embrace to pass the queries down using a search bar and the data warehouse is going to compute and bring the results back. This democratizes data warehouses to any user of any skill level.
Users also have the flexibility to utilize ThoughtSpot in many different ways, whether it's on-prem or in the cloud. In addition, ThoughtSpot selected SME as one of their first MSP partners. We can manage the entire deployment for you and make ThoughtSpot available for smaller data sets if that is what your deployment is looking like.
You can learn more on our dedicated ThoughtSpot page here or browse through nearly 100 videos we have produced on ThoughtSpot.
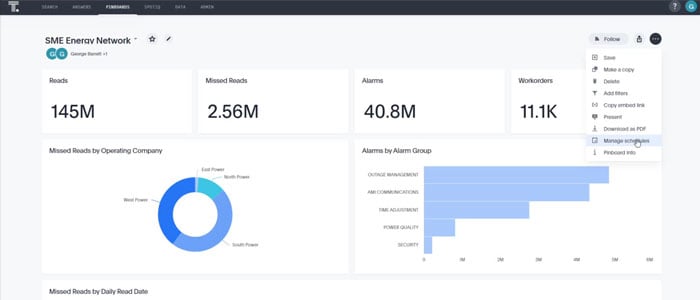

Qlik Sense Analytics Suite
SME also partners with Qlik to provide more granular self-service and interactive dashboards. Qlik is a comprehensive data analytics suite that allows users to visualize and report data in a number of ways, whether it be through dashboards, or pixel perfect reporting. The back end of Qlik has associative engines that will automatically connect to and associate data so users can see how their data is related and deploy data models faster than ever before. With advanced authoring and customization, users can integrate with a wide variety of different extensions and products. SME has partnerships with Vizlib, Blue Orbit Solutions, as well as Qlik, which have their own data catalog and data integration platforms to extend and make this suite the best that it can be. When a Qlik suite is extended like this, users can integrate with all its products, not just Qlik Sense but Qlik View as well. Utilizing dual licensing makes for a seamless transition moving from one platform to another.
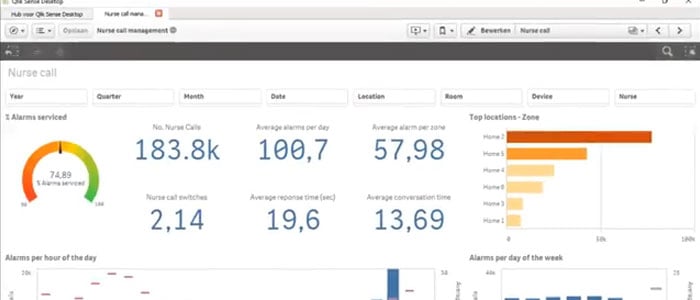
Vizlib
Staying in the Qlik Sense world is the product Vizlib. Vizlib creates value added products for Qlik Sense in the way that you can extend the platform to do more than just dashboarding. This includes financial reporting through the use of P&L's and Gantt charts for your project management. And now they have a collaboration aspect of it where you can use writeback tables to write data directly back to data sources, input forms, so you can create new data fields, as well as the teamwork chatbot that allows you to communicate with your users in real time.
Vizlib beautifully extends the Qlik Sense platform and allows you to do things that were never thought imaginable. This is why SME offers Vizlib to all of our Qlik Sense clients. You can learn more about Vizlib here or click the link below to watch our latest webinar in partnership with Vizlib.

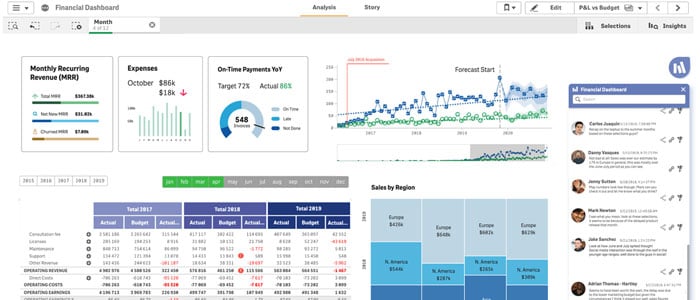
Power BI
On the flip side, SME partners with Power BI to provide an interactive and immersive dashboard. Power BI is great for utilizing self-service across the enterprise. The Microsoft model has a low cost, making it possible to provide this solution to literally any user. Power BI integrates really well with things such as SharePoint, Microsoft Teams, the Microsoft Power Platform, Office 365, Dynamics 365, and the hosting solution Azure.
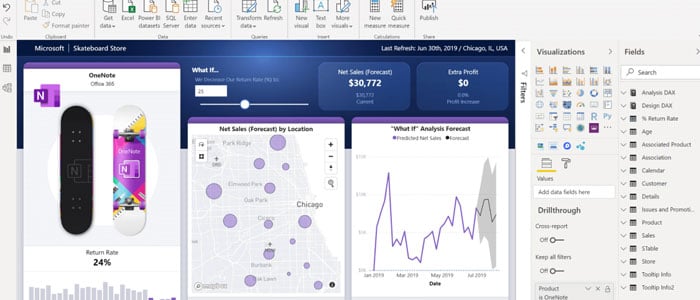
If a company is really embedded in the Microsoft products, this is going to be a very welcomed add-on that allows users to not only visualize reports but build them themselves. Finally, Power BI takes the skills and the power of Microsoft Excel and supercharges it. It utilizes reports that have been built in Excel inside of Power BI's rich visualization suite. We are seeing a lot of users that were typically heavy Excel power users transitioning to Power BI in a matter of hours.
Big Squid
Lastly, SME partners with the Big Squid Kraken program for citizen data science. Gone are the days where companies need to have a full data science team that has statistics, Python, and R backgrounds to build out models. This simplifies the creation and deployment of models because there's no code, it connects to data sources, and uses Auto ML (automated machine learning). Business analysts, even users in the executive suite, are able to utilize Big Squid to predict “What If” analyses and see how things are related or fine tune these models, again, without the use of code or any machine learning background.
Batch schedule syncs get on-time predictions that help enhance the data science suite. This is a great feature because it provides proprietary onboarding, which allows users to get oriented with AutoML in a matter of weeks. From there, the users are empowered to build their own models outside of the initial use case. This is called citizen data science, which is something that's going to help grow in the next couple of years, and SME is partnered with Big Squid to help blaze that trail.
Summary
As you can see, there's a lot of different moving parts into Data Analytics and Science space, but as the trends in the modern day grow and they change and evolve over time, SME is there to learn and help our customers move along that journey right there with them as things change.
From data storage through processing, governance, and visualizations, SME continues to support organizations where they need the most help. I hope you found this informative. If you are ready to see a demo of all of these solutions and how they can work together to solve complex data problems, click on the banner below and we will be in touch.

SME is very judicious in the products and services they recommend because they know they are in it for the long haul and value our partnership. I’ve received the same level of engagement and support from anyone I’ve worked with at SME – they listen before they react. I foresee a long and prosperous relationship with SME." ~ Grace Epperson, Chief Analytics Officer - 14 West